Thiết kế hệ thống thông tin có CSDL phân tán bao gồm:
- Phân tán và ch ọn những vị trí đặt dữ liệu;
- Các chương trình ứng dụng tại các điểm;
- Thiết kế tổ chức khai thác hệ thống đó trên nền mạng.
3.1.1. Khái niệm về phân tán dữ liệu
Khi thiết kế các hệ thống CSDL phân tán người ta thường tập trung xoay quanh các câu hỏi?
- Tại sao lại cần phải phân mảnh?
- Làm thế nào để thực hiện phân mảnh?
- Phân mảnh nên thực hiện đến mức độ nào?
- Có cách gì kiểm tra tính đúng đắn của việc phân mảnh?
- Các mảnh sẽ được cấp phát trên mạng như thế nào?
- Những thông tin nào sẽ cần thiết cho việc phân mảnh và cấp phát?
3.1.1.1. Các lý do phân mảnh
Trước tiên việc phân tán dữ liệu được thực hiện trên cơ sở cấp phát các tập tin cho các nút trên một mạng máy tính. Các nút mạng thường nằm ở các vị trí địa lý khác nhau trải rộng trên một diện tích lớn. Do vậy để tối ưu việc khai thác thông tin thì dữ liệu không thể để tập trung mà phải phân tán trên các nút c ủa mạng.
Hơn nữa một quan hệ không phải là một đơn vị truy xuất dữ liệu tốt nhất. Ví dụ như, nếu ứng dụng được thực hiện trên một bộ phận nhỏ các dữ liệu của quan hệ mà quan hệ đó nằm tại các vị trí khác nhau thì có thể gây ra những truy xuất thừa và hơn thế việc nhân bản các quan hệ làm tốn không gian b ộ nhớ. Do vậy phân rã một quan hệ thành nhiều mảnh, mỗi mảnh được xử lý như một đơn vị sẽ cho phép thực hiện nhiều giao dịch đồng thời. Một câu truy vấn ban đầu có thể được chia ra thành một tập các truy vấn con, các truy vấn này có th ể được thực hiện song song trên các m ảnh sẽ giúp cải thiện tốc độ hoạt động của hệ thống.
Tuy nhiên chúng ta c ũng sẽ gặp những rắc rối của việc phân mảnh, ví dụ nếu các ứng dụng có những xung đột sẽ ngăn cản hoặc gây khó khăn cho việc truy xuất dữ liệu. Phân rã các m ảnh nói chung làm tăng chi phí trong việc truy xuất dữ liệu. Một vấn đề nữa liên quan đến việc kiểm soát ngữ nghĩa và tính toàn vẹn dữ liệu.
3.1.1.2. Các kiểu phân mảnh
Thể hiện của các quan hệ chính là các b ảng, vì thế vấn đề là tìm những cách khác nhau để chia một bảng thành nhiều bảng nhỏ hơn. Rõ ràng có hai ph ương pháp khác nhau: Chia bảng theo chiều dọc và chia bảng theo chiều ngang. Chia dọc ta được các quan hệ con mà mỗi quan hệ chứa một tập con các thuộc tính của quan hệ gốc – gọi là phân m ảnh dọc. Chia ngang một quan hệ ta được các quan hệ con mà mỗi quan hệ chứa một số bộ của quan hệ gốc - gọi là phân mảnh ngang.
Ngoài ra còn có m ột khả năng hỗn hợp, đó là phân m ảnh kết hợp cách phân mảnh ngang và dọc. Tất nhiên quá trình phân mảnh gắn liến với vấn đề cấp phát và bài toán c ụ thể.
Ví dụ 3.1.
Trong ví dụ này chúng ta s ử dụng một CSDL của một công ty máy tính thực hiện các dự án phần mềm gồm các quan hệ:
DuAn(MaDuAn, Ten, KinhPhi, ViTri);
NhanVien(MaNV, Ten, ChucVu);
TrachNhiem(MaNV, MaDuAn, TrachNhiem, ThoiGianTG);
Luong(ChucVu, Luong).
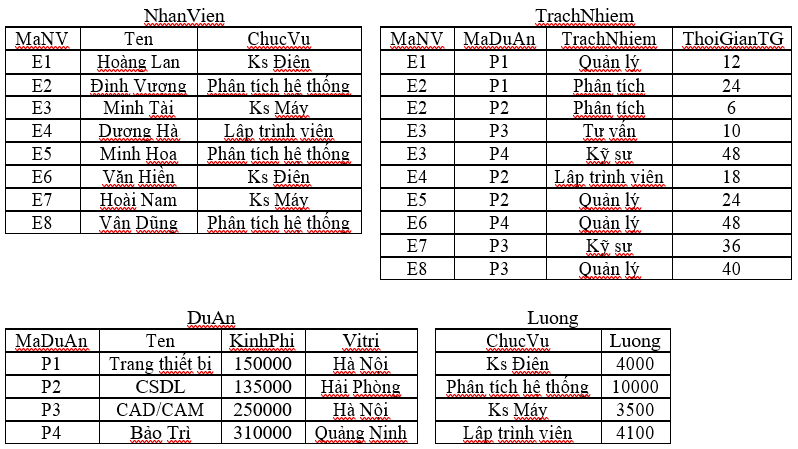
Người ta có thể chia ngang quan hệ DuAn Thành các quan h ệ con DuAn1, DuAn2. DuAn1 chứa những thông tin về các dự án có ngân sách dưới 200000$, còn DuAn2 l ưu các thông tin về các dự án có ngân sách trên 200000$.

Ngoài ra cũng có thể phân mảnh dọc quan hệ DuAn thành hai quan hệ DuAn3, DuAn4. DuAn3 chỉ chứa thông tin về ngân sách của các dự án, còn DuAn4 l ưu thông tin về tên và vị trí dự án. Điều cần lưu ý là khóa c ủa quan hệ DuAn phải xuất hiện trong cả hai mảnh.

3.1.1.3. Mức độ phân mảnh
Phân mảnh CSDL đến mức độ nào là m ột quyết định rất quan trong có ảnh hưởng đến hiệu năng thực hiện vấn tin. Mức độ phân mảnh có thể là từ thái cực không phân mảnh nào đến thái cực phân mảnh thành từng bộ hoặc từng thuộc tính. Tuy nhiên nếu phân mảnh quá nhỏ sẽ có những tác động không t ốt đến hoạt động khai thác CSDL. Vậy cần phải định ra được một mức độ phân mảnh thích hợp. Mức độ này sẽ tùy thu ộc vào từng CSDL và các ứng dụng CSDL cụ thể.
3.1.1.4. Quy tắc phân mảnh đúng đắn
Chúng ta s ẽ phải tuân thủ ba qui tắc trong khi phân mảnh mà chúng s ẽ đảm bảo CSDL không có thay đổi nào về mặt ngữ nghĩa sau khi phân mảnh.
1. Tính đầy đủ: Nếu một quan hệ R được phân mảnh thành các m ảnh R1, R2,…, RN thì mỗi mục dữ liệu có trong R phải có mặt trong một hoặc nhiều mảnh Ri.
2. Tính tái thiết được: Nếu một quan hệ R được phân mảnh thành R1, R2,…, RN thì cần phải định nghĩa một toán tử tái thiết Q sao cho:
R = QRi, i = 1..N.
Toán tử Q thay đổi tùy theo từng loại phân mảnh; thông thường khi phân mảnh ngang thì Q là phép toán h ợp còn phân m ảnh dọc là phép toán k ết nối.
3. Tính tách biệt: Nếu quan hệ R được phân mảnh ngang thành các m ảnh R1, R2,…, RN và mục dữ liệu ti nằm trong mảnh ri, thì nó sẽ không nằm trong các mảnh Rk với k ¹ j. Tiêu chuẩn này đảm bảo rằng các mảnh ngang sẽ tách biệt với nhau. Nếu quan hệ được phân mảnh dọc, các thuộc tính khóa chính phải được lặp lại trong mỗi mảnh. Vì thế trong trường hợp phân mảnh dọc, tính tách biệt chỉ được định nghĩa trên các trường không phải là khóa chính của một quan hệ.
3.1.1.5. Các kiểu cấp phát
Giả sử CSDL đã được phân mảnh hợp lý và cần quyết định cấp phát các mảnh cho các vị trí trên mạng. Khi dữ liệu được cấp phát, nó có thể được nhân bản hoặc duy trì một bản duy nhất.
Lý do c ần phải nhân bản là nhằm đảm bảo độ tin cậy và hiệu quả cho các câu vấn tin chỉ đọc. Nếu có nhiều bản sao của một mục dữ liệu thì chúng ta vẫn có cơ hội truy xuất được dữ liệu đố ngay cả khi hệ thống xẩy ra sự cố. Hơn nữa các câu vấn tin chỉ đọc truy xuất đến cùng m ột mục dữ liệu có thể cho thực hiện song song bởi vì các bản sao có mặt tại nhiều vị trí. Ngược lại câu vấn tin cập nhật có thể gây ra nhiều rắc rối bởi vì hệ thống phải bảo đảm rằng tất cả các bản sao phải được cập nhật chính xác. Vì vậy quyết định nhân bản cần được cân nhắc và phụ thuộc vào tỷ lệ giữa các câu vấn tin chỉ đọc và câu v ấn tin cập nhật. Quyết định này có ảnh hưởng đến tất cả các thuộc toán của hệ quản trị CSDL phân tán và các ch ức năng kiểm soát khác.
3.1.1.6. Các yêu cầu thông tin
Một điều cần lưu ý trong vi ệc thiết kế phân tán là quá nhi ều yếu tố có ảnh hưởng đến một thiết kế tối ưu. Tổ chức logic của CSDL, vị trí các ứng dụng, đặc tính truy xuất của các ứng dụng đến CSDL, và các đặc tính của hệ thống máy tính tại mỗi vị trí đều có ảnh hưởng đến các quyết định phân tán.
3.1.2. Phân mảnh ngang
Trong phần ngày chúng ta s ẽ bàn đến hai chiến lược phân mảnh:
- Phân mảnh ngang nguyên thủy: Phân mảnh ngang nguyên thủy của một quan hệ được thực hiện dựa trên các v ị từ được định nghĩa trên quan hệ đó.
- Phân mảnh ngang dẫn xuất: Là phân m ảnh một quan hệ dựa vào các v ị từ được định nghĩa trên một quan hệ khác.
3.1.2.1. Yêu cầu thông tin của phân mảnh ngang.
1. Thông tin v ề CSDL
Thông tin v ề CSDL là lược đồ toàn cục và các quan h ệ gốc. Trong ngữ cảnh này chúng ta c ần biết được các quan hệ sẽ kết lại với nhau bằng phép kết nối hay phép tính khác. Để thể hiện người ta thường dụng mô hình thực thể để biểu diễn các quan hệ với các mỗi liên kết giữa chúng.
Thông tin định lượng cần có là lực lượng của mỗi quan hệ R, đó là số bộ có trong R được ký hiệu là card(R).
2. Thông tin v ề ứng dụng
Để phân tán ngoài thông tin định lượng Card(R) ta còn c ần thông tin định tính cơ bản gồm các vị từ được dùng trong các câu v ấn tin. Lượng thông tin này ph ụ thuộc vào bài toán c ụ thể.
Cho lược đồ quan hệ R(U), U = A1, A2,…, AN trong đó mỗi Ai là một thuộc tính có miền giá trị dom(Ai). Một vị từ đơn giản P được định nghĩa trên R có d ạng:
P: Ai q <giá trị>
Trong đó q Î {=, <, <=, >=, >, <>}, Ai là một thuộc tính, <giá trị> Î dom(Ai).
Như vậy cho trước một lược đồ R, nếu các miền giá trị dom(Ai) là hữu hạn chúng ta có thể xác định được tập tất cả các vị từ đơn giản trên R.
Ví dụ: Với hình 3.1. các vị từ đơn giản của quan hệ DuAn:
P1: Ten = “Bảo trì”
P2: KinhPhi <= 200000
Trong các bài toán th ức tế các câu vấn tin thường chứa nhiều vị từ phức tạp hơn, là tổ hợp của các vị từ đơn giản. Ví dụ vị từ hội sơ cấp của các vị từ đơn giản. Bởi một biểu thức boolean luôn có thê biến đổi được thành dạng chuẩn hội cho nên chúng ta s ử dụng hội sơ cấp để biểu diễn các vị từ phức tạp.
Cho lược đồ quan hệ R(U), U = A1, A2,…, AN trong đó mỗi Ai là một thuộc tính có miền giá trị dom(Ai). Pr = {p1, p2,…, pt}. Tập các vị từ hội sơ cấp M = {m1, m2,…, mk} được định nghĩa như
sau:
mi = Ù p’j với 1 £ j £ t
Trong đó p’j = pj hoặc p’j = Øpj
Lưu ý: Phép l ấy phủ định một vị từ không phải lúc nào cũng thực hiện được.
Theo những thông tin định tính về các ứng dụng chúng ta cần biết hai tập dữ liệu:
1.. Số lượng các bộ có quan hệ sẽ được truy xuất bởi câu vấn tin được đặc tả theo một vị từ hội sơ cấp đã cho.
3. Tần số truy xuất và trong một số trường hợp là số truy xuất. Nếu Q = {q1, q2,…, qN} là các câu vấn tin, acc(qi) biểu thị cho số truy xuất của qi trong một khoảng thời gian đã cho hoặc trong quan hệ cụ thể.
3.1.2.2. Phân mảnh ngang nguyên thủy.
Phân mảnh ngang nguyên thủy được định nghĩa bằng một phép toán chọn trên các quan h ệ chủ của một lược đồ CSDL. Vì thế cho quan hệ R, các mảnh ngang của R là các R i với Ri = R(Ei), 1 £ i, £ k
Trong đó Ei là công thức chọn (hội sơ cấp) được sử dụng để có thể có được mảnh Ri. Chú ý rằng nếu Ei có dạng chuẩn hội, nó là một vị từ hội sơ cấp mi. Ri là các bộ của R thỏa mãn Ei.
Ví dụ:
Phân rã quan hệ DuAn thành các m ảnh ngang DuAn1, DuAn2 trong hình 3.1. được định nghĩa như sau:
DuAn1 = DuAn(KinhPhi £ 200000)
DuAn2 = DuAn(KinhPhi > 200000)
Một mảnh ngang Ri của quan hệ R có chứa tất cả các bộ R thỏa vị từ hội sơ cấp mi. Vì vậy cho một tập các vị từ hội sơ cấp M, số lượng các mảnh ngang cũng bằng số lượng các vị từ hội sơ cấp (tất nhiên một mảnh ngang có thể rỗng nếu vị từ không truy xuất đến bộ nào của quan hệ, các mảnh ngang có th ể bằng nhau nếu các vị từ tương đương). Tập các mảnh ngang này cũng thường được gọi là tập các mảnh hội sơ cấp.
Rõ ràng việc định nghĩa các mảnh ngang phụ thuộc vào cá v ị từ hội sơ cấp. Vì thế bước đầu tiên của mọi thuật toán phân mảnh là phải xác định tập các vị từ đơn giản sẽ tạo ra các vị từ hội sơ cấp. Tập vi từ này nói chung ph ụ thuộc vào mục tiêu và yêu cầu của bài toán.
Một số khái niệm quan trọng của các vị từ đơn giản là tính đầy đủ và cực tiểu của tập các vị từ.
Tập các vị từ đơn giản Pr được gọi là đầy đủ nếu và chỉ nếu xác suất của mỗi bộ của R(hoặc của các mảnh Ri) được truy xuất bởi các vị từ p Î Pr đều bằng nhau.
Lý do cần phải bảo đảm tính đầy đủ là vì các mảnh thu được theo tập vị từ đầy đủ sẽ nhất quán về mặt logic do tất cả chúng đều thỏa vị từ hội sơ cấp. Chúng cũng đồng nhất và đầy đủ về mặt thống kê theo cách mà ứng dụng truy xuất chúng.
Đặc tính thứ hai của tập vị từ là tính cực tiểu. Đây là một đặc tính cảm tính. Vị từ đơn giản phái có liên đới trong việc xác định một phân mảnh. Một vị từ mà không tham gia vào một tập phân mảnh nào thì có thể coi vị từ đó là thừa. Nếu tất cả các vị từ của Pr đều có liên đới và không có các vị từ tương đương thì Pr là cựu tiểu.
Chúng ta quy ước:
Thuật toán 3.1. COM-MIN Thuật toán tìm tập vị từ đầy đủ và cực tiểu Vào: Quan hệ R, tập các vị từ đơn giản Pr
Ra: Pr’ – tập các vị từ đơn giản đầy đủ và cực tiểu
Phương pháp:
0. Gọi F tập các mảnh hội sơ cấp Pr’ = Æ, F = Æ
1. "p Î Pr, nếu p phân hoạch R theo quy tắc 1
- Pr’ = Pr’ È {p}
- Pr = Pr – {p}
- F = F È {f} với f là một mảnh hội sơ cấp theo p
2. "p Î Pr nếu p phân hoạch một mảnh f Î F theo quy tắc 1
- Pr’ = Pr’ È {p}
- Pr = Pr – {p}
- F = F È {f} với f là một mảnh hội sơ cấp theo p
Lặp lại bước 2 cho đến khi nào không $p Î Pr’ phân hoạch một mảnh f Î F
3. "p Î Pr’ nếu $p’ mà p tương đương với p’
- Pr’ = Pr’ – {p}
- F = F – {f} với f là một mảnh hội sơ cấp theo p Sau bước 3 Pr’ là tập vị từ đầy đủ và tối thiểu cần tìm.
Bước tiếp theo của thiết kế phân mảnh ngang nguyên thủy là suy dẫn ra tập các vị từ hội sơ cấp có thể được định nghĩa trên các vị từ trong tập Pr’. Các vị từ hội sơ cấp này xác định các mảnh cho bước cấp phát.
Bước cuối của quá trình thiết kế là loại bỏ một số mảnh vô nghĩa. Điều này được thực hiện bằng cách xác định những vị từ mâu thuẫn với tập các phép kéo theo I. Chẳng hạn, nếu Pr’ = (P1, P2), trong đó
P1: A = giá trị 1
P2: A = giá trị 2
Và miền biến thiên của A là {giá tr ị 1, giá trị 2} rõ ràng I chứa hai phép kéo theo với khẳng định:
i1: (A = giá trị 1) ® Ø (A = giá trị 2)
i2: Ø(A = giá trị 1) ® (A = giá trị 2)
Bốn vị từ hội sơ cấp sau đây được định nghĩa theo Pr’
m1: (A = giá trị 1) Ù (A = giá trị 2)
m2: (A = giá trị 1) Ù Ø(A = giá trị 2)
m3: Ø(A = giá trị 1) Ù (A = giá trị 2)
m4: Ø(A = giá trị 1) Ù Ø(A = giá trị 2)
Trong trường hợp này các v ị từ hội sơ cấp m1 và m4 mâu thu ẫn với phép kéo theo I và vì thế bị loại khỏi M
Thuật toán 3.2. Thuật toán phân mảnh ngang nguyên thủy
Vào: Quan hệ R, tập các vị từ đơn giản Pr
Ra: M – tập các vị từ hội sơ cấp
Phương pháp:
0. Pr’ = COM-MIN(R,Pr)
Xác định tập M các vị từ hội sơ cấp
Xác định tập I các phép kéo theo giữa các Pi Î Pr’
1. "mi Î M nếu mi mâu thuẫn với I
M = M – {mi}
Sau bước này M là t ập các vị từ hội sơ cấp.
3.1.2.3. Phân mảnh ngang dẫn xuất
Phân mảnh ngang dẫn xuất được định nghĩa trên một quan hệ thành viên c ủa một đường nối dựa theo phép toán ch ọn trên quan hệ chủ nhân của đường nối đó. Như thế nếu cho trước một liên kết L, trong đó owner(L) = S và member(L) = R, các mảnh ngang dẫn xuất của R được định nghĩa là:
Ri = R
Si, 1 £ i £ k
Trong đó k là số lượng các mảnh được định nghĩa trên R, và S i = S(Ei), với Ei là công th ức định nghĩa phân mảnh ngang nguyên thủy Si.
Ví dụ: Xét liên kết giữa bảng Luong và NhanVien. Chúng ta có th ể nhóm các nhân viên thành hai nhóm tùy theo lương. Giả sử nhóm có lượng từ 4000$ trở xuống và nhóm lương trên 4000$. Hai mảnh NhanVien1 và NhanVien2 được định nghĩa như sau:
NhanVien1 = NhanVien >< Luong1
NhanVien2 = NhanVien >< Luong2
Luong2
Trong đó
Luong1 = Luong(Luong £ 4000)
Luong2 = Luong(Luong > 4000)
Kết quả thu được như sau:

Muốn thực hiện phân mảnh ngang dẫn xuất chúng ta cần ba nguyên liệu: Tập các phân hoạch của quan hệ chủ (chẳng hạn Luong1 và Luong2 trong ví dụ trên), quan hệ thành viên, và t ập các vị từ nối giữa quan hệ chủ và quan hệ thành viên (ch ẳng hạn NhanVien.ChucVu = Luong.ChucVu). Cũng có một vấn đề phức tạp phải chú ý, trong lược đồ CSDL chúng ta hay gặp nhiều đường nối đến một quan hệ R. Như thế có thể có nhiều cách phân mảnh ngang dẫn xuất cho R. Quyết định chọn cách phân mảnh nào cần dựa trên hai tiêu chu ẩn sau:
1. Phân mảnh có đặc tính nối tốt hơn;
2. Phân mảnh được sử dụng trong nhiều ứng dụng hơn.
3.1.2.4. Kiểm tra tính đúng đắn của phân mảnh ngang
1. Tính đầy đủ
Tính đầy đủ của một phân mảnh ngang nguyên thủy dựa vào các v ị từ chọn được dùng. V ới điều kiện các vị từ chọn là đầy đủ, phân mảnh thu được cung được bảo đảm là đầy đủ, bởi vì cơ sở của thuật toán phân mảnh là một tập các vị từ cực tiểu và đầy đủ. Tính đầy đủ sẽ được bảo đảm với điều kiện là không có sai sót x ẩy ra khi định nghĩa tập vị từ đầy đủ và cực tiểu Pr. Tính đầy đủ của phân mảnh ngang dẫn xuất có hơi khác. Khó khăn là do vị từ định nghĩa phân mảnh có liên quan đến hai quan hệ.
Gọi R là quan hệ thành viên c ủa một liên kết mà chủ là quan hệ S được phân mảnh thành Fs = {S1, S2,…, SN}. A là thuộc tính nối giữa R và S. Vậy đối với mỗi bộ t của R, phải có một bộ t’ sao cho t.A = t’.A
Quy tắc này được gọi là ràng bu ộc toàn vẹn hay toàn vẹn tham chiếu, bảo đảm mọi bộ trong các mảnh của quan hệ thành viên đều nằm trong quan hệ chủ.
2. Tính tái thiết được
Tái thiết một quan hệ toàn cục từ các mảnh được thực hiện bằng toán tử hợp trong cả phân mảnh ngang nguyên thủy lẫn dẫn xuất. Vì thế một quan hệ R với phân mảnh FR = {R1, R2,…, RN},
chúng ta có R = È Ri, "Ri Î FR.
3. Tính tách biệt
Chúng ta có th ể dễ dạng thấy rằng tính tách rời của phân mảnh nguyên thủy là rõ ràng theo cách phân mảnh của ta. Với phân mảnh dẫn xuất, tính tách rời sẽ được bảo đảm nếu các vị từ hội sơ cấp xác đinh phân mảnh có tính loài trừ lẫn nhau.
3.1.3. Phân mảnh dọc.
Phân mảnh dọc một quan hệ r sẽ sinh ra các mảnh r1, r2,…, rN mỗi mảnh chứa một tập con thuộc tính của R và cả khóa của r. Mục đích của phân mảnh dọc là phân ho ạch một quan hệ thành một tập các quan hệ nhỏ hơn để nhiều ứng dụng có thể chỉ chạy trên một quan hệ. Trong ngữ cảnh này, một phân mảnh tối ưu là một phân mảnh sinh ra một lược đồ phân mảnh cho phép giảm đến tối da thời gian thực thi các ứng dụng chạy trên các m ảnh đó.
Phân mảnh dọc đã được nghiên cứu trong ngữ cảnh của các hệ CSDL tập trung. Lý do chính là sử dụng nó làm một công c ụ thiết kế cho phép các vấn tin làm việc trên các quan h ệ nhỏ hơn vì thế giảm bớt số truy xuất và tiết kiệm bộ nhớ. Một trong số các phương pháp phân mảnh dọc đã nghiên cứu trong mô hình CSDL quan hệ là việc chuẩn hóa các quan hệ về các dạng chuẩn cấp cao.
Bên cạnh phương pháp chuẩn hóa các quan hệ còn có nh ững phương pháp khác và chúng thường gắn với mục tiêu của bài toán.
3.1.4. Cấp phát.
Bài toán c ấp phát:
Giả sử rằng có một tập các mảnh F = {F1, F2,…, FN} và một mạng máy tính bao gồm các vị trị S
= {S1, S2,…, SM} trên đó có một tập các ứng dụng dạng Q = {q1, q2,…, qk} đang chạy. Bài toán c ấp phát là tìm một phân phối “tối ưu” của F cho S.
Tính tối ưu có thể được định nghĩa ứng với hai số đo:
- Chi phí nhỏ nhất: Hàm chi phí gồm có chi phí lưu mỗi mảnh Fi tại vị trí Sj, chi phí vấn tin Fi
tại vị trí Sj, chi phí cập nhật Fi tại tất cả mọi vị trí chứa nó và chi phí truyền dữ liệu. Vì thế bài toán cấp phát cố gắng tìm một lược đồ cấp phát với hàm chi phí tổ hợp thấp nhất.
- Hiệu quả: Chiến lược cấp phát được thiết kế nhằm duy trì một hiệu quả lớn nhất đó là hạ thấp thời gian đáp ứng và tăng tối đa lưu lượng hệ thống tại mỗi vị trí.
Nói chung bài toán c ấp phát tổng quát là bài toán ph ức tạp, vì thế các nghiên cứu đều tập trung tìm ra các giải thuật heuristic tốt để có thể có được các lời giải tối ưu. Để phân biệt bài toán c ấp phát tập tin truyền thống với cấp phát mảnh trong các thiết kế CSDL phân tán, chúng ta gọi b ài toán thứ nhất là bài toán c ấp phát tập tin, và bài toán sau là bài toán c ấp phát CSDL.
Hiện không có một mô hình heuristic tổng quát nào nhận một tập các mảnh và sinh ra một chiến lược cấp phát gần tối ưu ứng với các loại ràng buộc. Các mô hình đã được phát triển chỉ mới đưa ra một số giả thiết đơn giản hóa và dễ áp dụng cho một số cách đặt vấn đề cụ thể.
Thông tin cho c ấp phát:
Thông tin v ề CSDL:
Để thực hiện phân mảnh ngang, chúng ta đã định nghĩa độ tuyển hội sơ cấp. Bây giờ chúng ta cần mở rộng định nghĩa đó cho các mảnh và định nghĩa độ tuyển của một mảnh Fj ứng với câu vấn tin qi. Đây là số lượng các bộ của Fj cần được truy xuất để xử lý qi. Giá trị này được ký hiệu là
Seli(Fj).
Một loại thông tin khác trên các m ảnh là kích thước của chúng. Kích thước một mảnh Fj được cho bởi: size(Fj) = card(Fj) * Length(Fj)
Trong đó length(Fj) là chiều dài tính theo byte của một bộ trong mảnh Fj
Thông tin v ề ứng dụng:
Phần lớn các thông tin có liên quan đến ứng dụng đều đã được biên dịch trong khi thực hiện phân mảnh nhưng cung cần một số ít nữa cho mô hình cấp phát. Hai số liệu quan trọng là số truy
xuất đọc do câu vấn tin qi thực hiện trên mảnh Fj trong mỗi lần chạy của nó – ký hi ệu là RRij. Và tương ứng là các truy xu ất cập nhật – ký hi ệu là URij.
Chúng ta định nghĩa hai ma trận UM và RM với các phần tử tương ứng uij và rij được đặc tả như
sau
- uij = 1 nếu vấn tin qi có c ập nhật mảnh Fj, ngược lại sẽ bằng 0
- rij = 1 nếu vần tin qi cần đọc mảnh Fj, ngược lại sẽ băng 0.
Một vectơ O gồm các giá trị 0(i) cũng được định nghĩa, với 0(i) đặc tả vị trí đưa ra câu vấn tin qi. Cuối cúng để định nghĩa ràng buộc thời gian đáp ứng, thời gian đáp ứng tối đa được phép của mỗi ứng dụng cũng cần phải được đặc tả.
Thông tin v ề vị trí:
Với mỗi vị trí chúng ta cần biết về khả năng lưu trữ và xử lý của nó. Hiển nhiên là nh ững giá trị này có th ể được tính bằng các hàm thích hợp hoặc bằng các phương pháp đánh giá đơn giản. Chi phí đơn vị để lưu trữ dữ liệu tại các vị trị Sj được ký hiệu là USCj. Cũng cần phải đặc tả số đo chi phí LPCj là chi phí xử lý một đơn vị công việc tại vị trí Sj. Đơn vị công việc cần phải giống với đơn vị của RR và UR.
Thông tin v ề mạng:
Trong mô hình đang xét, chúng ta giả sử có tồn tại một mạng đơn giản, trong đó chi phí truyền mỗi bó giữa hai vị trí Si và Sj. Để có thể tính được số lượng thông báo, chúng ta dùng fsize làm kích thước (tính theo byte) của một bó dữ liệu.
Được cập nhật: hôm qua lúc 13:03:29 | Lượt xem: 9462


